
TCL REGEX IN NUKE
Regular expression or Regex has been invented in the 50`s and been around since the 60's and it can be found in most high level programming languages and so TCL is no exception.
Regex is used to find/replace matches or NOT matches in strings.
Generally, this is a module that many programmers feel really strongly about be it negative or positive for multiple reasons but mostly because this is a "language" that can be brutally abused like in this imfamous example that is about validating an email address.
If you need some help making up your mind about Regex here is a really fantastic assessment.
I am not going to debate whether you should use it or not, rather would like to focus on explaining some basics and show some useful things you can do with regex in Nuke as for most compositors this might seem like something a cat would type walking across the keyboard. Also, because I haven't met but two examples online in which tokeru and Gabor L. Toth used a bit of regex, it felt like a good opportunity to introduce this module to fellow compositors.
Synopsis
Let's start with how a regex code should look like in Nuke!

[ regexp -inline {\d+} [value name]]
There are a few parts in here that we can break down:
1 [ ] - First of all, every TCL code in Nuke should be in square brackets.
2 regexp - Starting a code with calling the module.
3 -inline - Regex supports multiple switches that should start with " - " and determines the output.
4 {\d+} - This is where the interesting part happens which is called expression string. This part should be in curly brackets "{ }".
5 [value name] - The string we would like to make the regex run on is the match variable.
Re types
regexp - Match a regular expression against a string
regsub - Perform substitutions based on regular expression pattern matching
Switches
For both types we have multiple different switches offered for us.
As this is a tutorial for Nuke users and not for computer scientists I will focus on the ones that can be more useful for us and not making a list of all of them ( You can find a list of all of them following the links added to the re types above ).
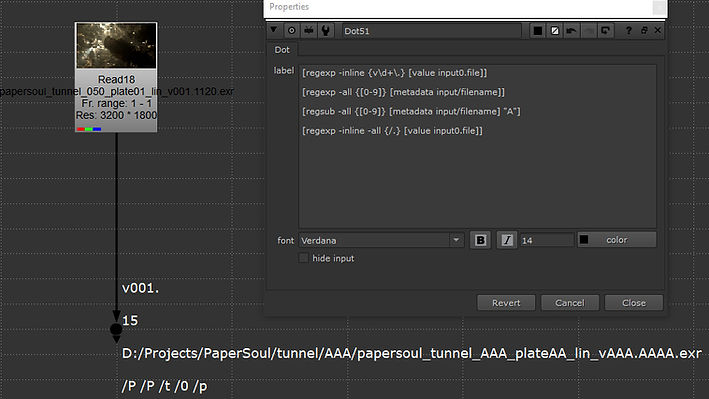
-inline
Works with regexp and causes the command to return, as a list. Possibly the one that we would use most frequently!
Returns the version number of the file value:
[regexp -inline {v\d+\.} [value input0.file]]
-all
Works both with regexp and regsub requiring a slightly different syntax.
Returns the number of all possible matches in the match variable:
[regexp -all {[0-9]} [metadata input/filename]]
Returns the match variable as a string replaced with a given string (A in this case) at all matches:
[regsub -all {[0-9]} [metadata input/filename] "A"]
-inline -all
This combination of switches works with regexp.
Returns a list with all the matches in the match variable.
[regexp -inline -all {/.} [value input0.file]]
Expression string
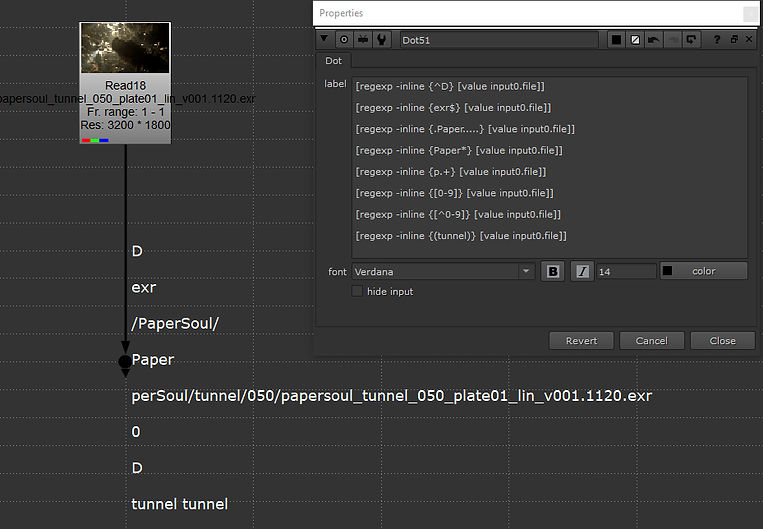
^
Matches the beginning of a string
[regexp -inline {^D} [value input0.file]]
$
Matches the end of a string
[regexp -inline {exr$} [value input0.file]]
.
Matches any single character
[regexp -inline {.Paper.....} [value input0.file]]
*
Matches any count (0-n) of the previous character
[regexp -inline {Paper*} [value input0.file]]
+
Matches any count, but at least 1 of the previous character
[regexp -inline {p.+} [value input0.file]]
[...]
Matches any character of a set of characters
[regexp -inline {[0-9]} [value input0.file]]
[^...]
Matches any character *NOT* a member of the set of characters following the ^.
[regexp -inline {[^0-9]} [value input0.file]]
(...)
Groups a set of characters into a subSpec.
[regexp -inline {(tunnel)} [value input0.file]]

Escapes are which begin with a \ representing certain characters or classes. There are more escapes that I am listing here but those seemed less likely to be needed by a Nuke user, nevertheless you can find them following a link above.
\d
Matches with a decimal digit. ( Added + so it returns the rest of the following matches )
[regexp -inline {\d+} [value input0.file]]
\D
Matches with a none decimal digit ( Added + so it returns the rest of the following matches )
[regexp -inline {\D+} [value input0.file]]
\w
Matches with any letter or digit.
[regexp -inline {\w} [value input0.file]]
\W
Matches with any none letter or digit.
[regexp -inline {\W+} [value input0.file]]
\m
Matches only the beginning of the word.
[regexp -inline {\mP......} [value input0.file]]
\M
Matches only the end of the word.
[regexp -inline {\M.exr} [value input0.file]]
\y
Matches only the beginning or the end of the word.
[regexp -inline {\y...} [value input0.file]]
\Y
Matches only NOT the beginning or the end of the word.
[regexp -inline {\Y...} [value input0.file]]
Match Variable
There is a wide range of possibilites on how to find a string in Nuke to feed to regex!
If in need of an inspiration you can visit two of my previous tutorials:
Useful combinations
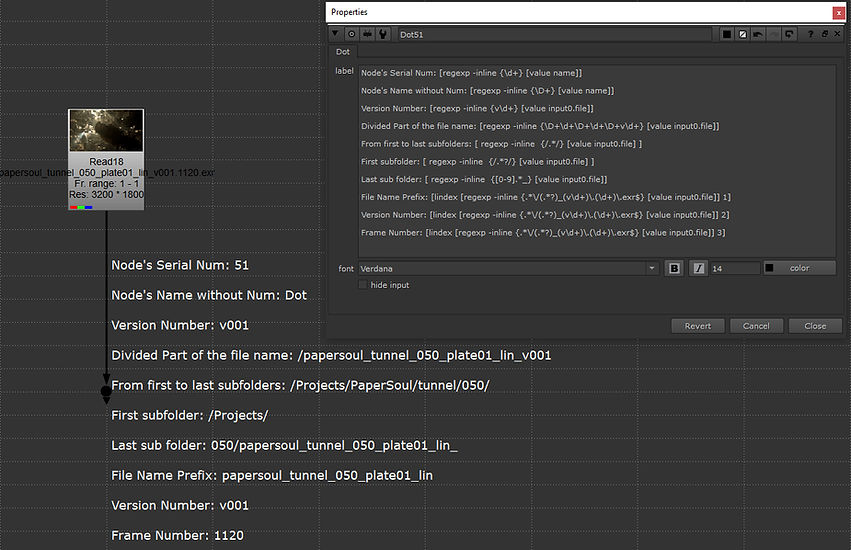
Node's Serial Num: [regexp -inline {\d+} [value name]]
Node's Name without Num: [regexp -inline {\D+} [value name]]
Version Number: [regexp -inline {v\d+} [value input0.file]]
Divided Part of the file name: [regexp -inline {\D+\d+\D+\d+\D+v\d+} [value input0.file]]
From first to last subfolders: [ regexp -inline {/.*/} [value input0.file] ]
First subfolder: [ regexp -inline {/.*?/} [value input0.file] ]
Last subfolder: [ regexp -inline {[0-9].*_} [value input0.file]]
File Name Prefix: [lindex [regexp -inline {.*\/(.*?)_(v\d+)\.(\d+)\.exr$} [value input0.file]] 1]
Version Number: [lindex [regexp -inline {.*\/(.*?)_(v\d+)\.(\d+)\.exr$} [value input0.file]] 2]
Frame Number: [lindex [regexp -inline {.*\/(.*?)_(v\d+)\.(\d+)\.exr$} [value input0.file]] 3]
Useful links
Huge thanks to Paul Barton for helping to understand all this! ( as much as I could )

Hope you will find it useful!